a. Tên nhiệm vụ: Nghiên cứu phát triển tường lửa ứng dụng web đảm bảo an toàn thông tin cho các cổng/trang thông tin điện tử của các cơ quan Nhà nước tỉnh Bình Dương
b. Đơn vị chủ trì: Trường Đại học Công nghệ thông tin - Đại học Quốc gia Tp.HCM
c. Chủ nhiệm đề tài: TS. Phạm Văn Hậu và cá nhân tham gia thực hiện:
1. PGS.TS. Lê Trung Quân
2. ThS. Nguyễn Tấn Cầm
3. ThS. Trần Bá Nhiệm
4. ThS. Trần Thị Dung
5. ThS Nguyễn Duy
6. KS Lê Đặng Bảo Chương
d. Mục tiêu nghiên cứu:
- Đề ra giải pháp dựa vào phần mềm WAF mã nguồn mở nhằm bảo vệ ANTT cho các cổng trang thông tin điện tử ở Bình Dương. Giải pháp được đề nghị được triển khai thực tế tại một đơn vị ở sở TT&TT và phải thể hiện được khả năng vượt trội so với các giải pháp mã nguồn mở đang tồn tại.
đ. Kết quả nghiên cứu (tóm tắt)
Trong bài báo này chúng tôi nghiên cứu phương pháp nhằm mở rộng ModSecurity, cho phép ModSecurity hoạt động ở chế độ blacklist và whitelist. Để hỗ trợ chế độ whitelist, hai công việc sau đây cần được thực hiện. Bước một, huấn luyện hệ thống bắt đầu bằng thu thập dữ liệu trao đổi giữa trình duyệt và máy chủ web lưu trữ riêng theo từng URL. Bước hai, dựa vào thông tin thu thập được chúng tôi xây dựng profile cho từng URL. Profile này mô tả đặc tính của các trường dữ liệu tương ứng xuất hiện trong câu truy vấn. Các đặc tính này được chia thành hai nhóm: nhóm đặc tính cho từng trường ví dụ như độ dài, tập các ký tự đã từng xuất hiện, có sự xuất hiện của keyword, sự phân bố ký tự và nhóm đặc tính cho cả câu truy vấn ví dụ như số trường (attribute), thứ tự các attributes. Bước hai phát hiện tấn công, chúng tôi sử dụng các đặc tính này nhằm xác định câu truy vấn có phải là một tấn công hay không. Chúng tôi đã phát triển hệ thống và thử nghiệm trên các tập dữ liệu dùng để đánh giá các tường lửa ứng dụng web là CSIC. Thực hiện cho thấy hướng tiếp cận của chúng tôi rất khả quan với độ chính xác lên đến gần 96.3%. Để tăng tính an toàn cho hệ thống, chúng tôi triển khai khả năng tự học song song với sử dụng bộ luật chuẩn của ModSecurity.
I. GIỚI THIỆU
Các hình thức được sử dụng phổ biến nhằm bảo vệ ứng dựng web có thể chia thành 3 nhóm như sau: i) Bảo vệ trong quá trình phát triển ứng dụng web ii) Đánh giá an toàn các ứng dụng đã tồn tại iii) Sử dụng các giải pháp nhằm bảo vệ ứng dụng đã tồn tại trong lúc thực thi. Trong đề tài này, chúng tôi đi theo hướng cuối cùng này. Trong nhóm này phương thức phổ biến nhất là dùng tường lửa. Các loại tường lửa phổ biến sử dụng các thông tin ở tầng mạng và vận chuyển (chủ yếu là số cổng, loại giao thức) để ngăn chặn các tấn công, truy cập trái phép. Tuy nhiên, các giải pháp tường lửa này cho phép gói tin đi đến các dịch vụ nhằm phục vụ rộng rãi công chúng như máy chủ web, FTP. Do đó, việc bảo vệ các dịch vụ này được chuyển về việc tạo ra các ứng dụng với mã nguồn an toàn. Hiện tại, có nhiều tài liệu hướng dẫn lập trình an toàn, tuy nhiên, không phải lúc nào các nhà phát triển ứng dụng cũng nắm vững, làm theo các hướng dẫn này. Chưa kể, do việc phát triển ứng dụng máy tính hầu hết được thực hiện bởi con người, việc mắc lỗi trong quá trình thiết kế, cài đặt là điều không thể tránh khỏi. Việc tạo ra chương trình không có lỗ hổng là điều rất khó (nếu không nói là không thể). Cách khác để bảo vệ các ứng dụng như cổng/ trang thông tin điện tử là sử dụng các hệ thống phát hiện/chống tấn công (Intrusion Detection System-IDS/Intrusion Prevention System-IPS). Có hai hướng tiếp cận chính trong việc phát triển các IDS/IPS. Giải pháp sử dụng mẫu nhận dạng (signature-based IDS) và giải pháp dựa vào hành vi (behavior-based IDS). Các kĩ thuật dựa vào mẫu nhận dạng phát hiện tấn công bằng cách so sánh nội dung gói tin với các dấu hiệu nhận dạng (signature) từ cơ sở dữ liệu đã tạo sẵn. Nếu có sự trùng khớp thì hệ thống sẽ cảnh báo có tấn công. Đại diện cho hướng tiếp cận này là Snort [1]. Ưu điểm của hướng tiếp cận này là độ chính xác cao (ít lỗi dạng false positive) tuy nhiên nhược điểm là nó không thể phát hiện các dạng tấn công mới. Ngoài ra, với số lượng mã độc không ngừng tăng lên rất khó trong việc cập nhật tập mẫu nhận dạng tấn công này.
Hình 1 thể hiện số lượng mẫu nhận dạng mà Symantec đã sử dụng cho đến năm 2011. Như chúng ta có thể quan sát được có đến gần 16 triệu mẫu.
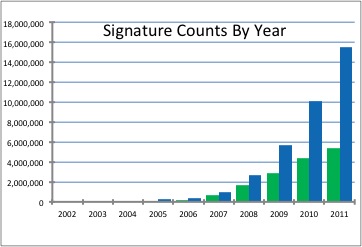
Hình 1. Số lượng signatures mã độc của Symantec theo từng năm và cộng dồn
Ngoài ra, có một số lỗ hổng bảo mật liên quan đến các phần mềm được phát triển riêng lẻ. Việc tạo ra các dấu hiệu nhận dạng tấn công đúng cho các trường hợp này là rất khó và mất thời gian. Đối với kĩ thuật dựa vào hành vi (behavior-based IDS), IDS/IPS sẽ xây dựng profile mô tả hoạt động bình thường của hệ thống mà chúng bảo vệ. Nếu đặc tính của dữ liệu (traffic) khác với profile mà nó đã học trước đó, hệ thống IDS/IPS sẽ thông báo là có tấn công. Đại diện cho hướng tiếp cận này là Bro [2]. Ưu điểm của phương pháp tiếp cận này là có thể phát hiện được các dạng tấn công mới. Tuy nhiên nhược điểm là tỉ lệ cảnh báo sai cao (false positive).
Sự khác biệt giữa IPS và IDS là IPS có khả năng ngăn các cuộc tấn công còn IDS chỉ đơn thuần là phát hiện và cảnh báo. Vấn đề của IDS/IPS là chúng không hiểu được logic của giao thức. Ví dụ, chúng không thể biết được một gói tin HTTP bị sai định dạng. Đây lại có thể là một kĩ thuật được sử dụng để tấn công máy chủ web.
Để giải quyết vấn đề này tường lửa mức ứng dụng web (Web Application firewall–WAF) ra đời. Kiến trúc logic của WAF được trình bày trong Hình 2.
Hình 2. Kiến trúc luận lý của tường lửa ứng dụng web
Bằng cách hiểu được giao thức HTTP, tức là hiểu được ứng với request thì response như thế nào, WAF có thể phát hiện các dạng tấn công mà IDS/IPS không thể phát hiện. Ví dụ, các dạng tấn công mà WAF có thể phát hiện như: SQL injection, cross-site scripting, session hijacking, parameter/URL tampering, buffer overflows.
Về mặt phân loại, các WAF được chia làm hai loại như sau: Network-based application firewalls và Host-based application firewalls. Network-based application firewall là tường lửa hoạt động ở tầng ứng dụng của chồng giao thức. Nó còn được gọi là reverse-proxy firewall. Tường lửa loại này có thể chạy trên máy riêng biệt (appliance device) hoặc chạy trên một máy tính thông thường nằm giữa máy chủ và trình duyệt. Bằng cách xem xét nội dung của gói tin, tường lửa có thể chặn kết nối khi truy cập vào một số websites, câu trả lời chứa viruses. Ngoài ra, trong thực tế, người ta có thể triển khai tường lửa ứng dụng dạng network-based trực tiếp lên máy chủ cần được bảo vệ. Dạng triển khai này được gọi là embedded-mode. Khác với loại network-based application firewall, host-based application firewall phải được triển khai trên máy mà nó cần bảo vệ, khi đó tường lửa sẽ theo dõi input, output, lời gọi hệ thống của bất kì ứng dụng nào chạy trên máy đó. Để thực hiện được điều này, host-based application firewall sẽ chèn vào giữa tầng ứng dụng và tầng thấp hơn trong mô hình OSI. Ví dụ cho tường lửa loại này là AppArmor. AppArmor xây dựng profile vào dựa vào hoạt động của ứng dụng. Profile đó sẽ giới hạn khả năng của ứng dụng. AppArmor hoạt động theo cơ chế MAC (Mandatory Access Control).

Hiện tại tồn tại nhiều giải pháp WAF mã nguồn mở chẳng hạn như: ModSecurity, AQTRONIX Web Knight. Các phần mềm mã nguồn mở có những ưu điểm tuy nhiên cũng có những khuyết điểm của nó. Lấy ví dụ phần mềm WAF mã nguồn mở được sử dụng nhiều nhất là Mod Security, nó không có giao diện người dùng, chúng ta chỉ có thể tương tác qua dòng lệnh và thực hiện cấu hình ở rất nhiều file cấu hình khác nhau. Ngược lại, phần mềm AQTRONIX Web Knight lại được sử dụng chủ yếu để bảo vệ các web server IIS trên máy Windows. Điều này là minh chứng cho nhu cầu đánh giá và hiểu rõ ưu nhược điểm của các sản phẩm này là cần thiết.
Theo tác giả của [3], có ba loại lỗ phổ biến của ứng dụng web như sau: Lỗi liên quan đến dữ liệu do người dùng nhập vào [3, 4, 5], lỗi liên quan đến quản lý phiên làm việc [6, 7, 8] và lỗi liên quan đến logic của ứng dụng web [9, 10, 11]. Chúng ta dễ nhận thấy rằng, đây là một cách phân loại lỗi khác với OWASP. Tuy nhiên, chúng ta cũng thấy rằng hầu hết các loại lỗi liệt kê bởi OWASP thuộc về trường hợp thứ nhất đó là liên quan đến kiểm tra dữ liệu đầu vào. Do đó, trong dự án này, chúng tôi tập trung vào giải pháp phát hiện tấn công liên quan đến dữ liệu đầu vào. Về khía cạnh này, chúng tôi còn chia thành các nhóm kỹ thuật như sau:
- Phát triển framework [12, 13, 14], công cụ nhằm tạo ra các ứng dụng web an toàn với tấn công liên quan đến việc không kiểm tra dữ liệu đầu vào
- Kiểm thử ứng dụng nhằm phát hiện lỗi liên quan đến dữ liệu nhập vào: Kỹ thuật phổ biến được sử dụng trong trường hợp này là phân tích dựa vào đánh dấu dữ liệu (taint analysis) [15, 16, 17]. Kỹ thuật này nhằm phát hiện ra luồng dữ liệu bắt nguồn từ người dùng được lan truyền đến các điểm xử lý nguy hiểm cho hệ thống. Ví dụ, dữ liệu người dùng nhập vào được chuyển xuống cơ sở dữ liệu. Một cách tổng quan, kỹ thuật phân tích dựa vào đánh dấu dữ liệu được chia thành hai nhóm là phân tích tĩnh và phân tích động. Trong đó, phân tích tĩnh liên quan đến tất cả các kỹ thuật nhằm xem xét mã ứng dụng mà không thực thi chúng. Ngược lại, kỹ thuật phân tích động thực thi ứng dụng trong một môi trường (sandbox) và quan sát các luồng dữ liệu nhằm phát hiện ra các luồng nhạy cảm.
- Kỹ thuật liên quan đến bảo vệ ứng dụng khi thực thi: Trong nhóm này, có hai nhóm giải pháp được sử dụng đó là sử dụng phân tích gắn nhãn dữ liệu (giống như phần kiểm thử) [18, 19, 20] và kỹ thuật không sử dụng gắn nhãn [21, 22, 23].
Sau đây, chúng tôi trình bày một số công trình tiêu biểu liên quan đến kỹ thuật bảo vệ ứng dụng khi thực thi mà không sử dụng gắn nhãn dữ liệu.
Tác giả của [24] đề xuất mô hình phát hiện tấn công dựa vào sự kết hợp giữa chương trình (programs), tham số của chương trình và giá trị của tham số. Trong giai đoạn học, bộ nhận dạng sử dụng mô hình để mô hình hoá thuộc tính của các tham số (chẳng hạn độ dài dữ liệu, miền giá trị, ...) hoặc là thuộc tính của câu truy vấn (câu truy vấn dạng GET được trình bày trong Hình 3). Các thông tin này sau đó được dùng để xây dựng profile cho ứng dụng tương ứng. Nhiệm vụ của các mô hình này là ứng với một câu truy vấn thì mô hình sẽ trả về xác suất của các thành phần tương ứng (của các tham số, của cả câu truy vấn) và các xác suất này được kết hợp lại để tính ra độ bất thường của câu truy vấn. Nếu độ bất thường này lớn hơn một ngưỡng cho trước thì câu truy vấn được cho là tấn công. TokDoc [25] cũng sử dụng mô hình nhận dạng hành vi bất thường để phát hiện tấn công. Không giống giải pháp đã trình bày trước đó, TokDoc ra quyết định ở mức parameter, có thể phục hồi dữ liệu nếu nghi ngờ nó là dữ liệu tấn công.
Hệ thống phát hiện tấn công trên cơ sở giám sát hệ thống từ bên trong (behavior-based interior system detection): để minh họa hoạt động của hệ thống này, chúng tôi giới thiệu trường hợp mà hệ thống IDS được xây dựng để phát hiện dạng tấn công lợi dụng lỗi logic của ứng dụng web để thực hiện điều chỉnh workflow của ứng dụng.
Để hiểu rõ hơn về loại tấn công này, chúng ta xem xét tình huống trong đó một ứng dụng web thực hiện thanh toán trực tuyến qua nhiều bước (trong trường hợp này là 4 bước như trình bày trong Hình 4). Ở tình huống bình thường, các bước được lần lượt thực hiện là step 1, step 2, step 3, và step 4. Giả sử vì một lí do nào đó mà ứng dụng không kiểm tra được ràng buộc này, người dùng có thể thực hiện được step 3 nếu biết URL tương ứng mà không cần thực hiện step 2. Theo như trình bày ở hình trên, người dùng chỉ được yêu cầu thanh toán phí vận chuyển thay vì toàn bộ tiền mua sản phẩm, thuế và phí vận chuyển.
Các tác giả của [26] xây dựng công cụ Swaddler có khả năng phát hiện các tấn công web. Công cụ Swaddler nhận dạng tấn công dựa vào sự quan sát ứng dụng từ bên trong. Ý tưởng chính là Swaddler theo dõi trạng thái của ứng dụng và xây dựng mô hình để mô tả hoạt động bình thường của ứng dụng, nếu nhận thấy khi vận hành hệ thống không hoạt động theo mô hình đã quan sát được thì kết luận là tấn công. Cụ thể hơn, Swaddler chia ứng dụng ra thành các khối căn bản. Khối căn bản là những đoạn mã không có điều kiện rẻ nhánh. Hệ thống bao gồm hai thành phần chính là Sensor và Analyzer. Ở giai đoạn học (như mô tả trong Hình 5) Sensor ghi nhận các biến và giá trị tương ứng, tập hợp các biến và giá trị này được tập hợp lại thành event. Bộ phận phân tích Analyzer xây dựng profile từ các event để mô tả đặc tính của các biến trong khối căn bản tương ứng. Ở giai đoạn phát hiện tấn công (Hình 6), event được chuyển cho Analyzer để phát hiện tấn công bằng cách so sánh với profile của khối căn bản tương ứng.
II. MÔ HÌNH HỆ THỐNG
Chúng tôi dựa vào công trình [24] và thực hiện những cải tiến khi thực hiện triển khai trong thực tế. Về mô hình tổng quan thì web client và web server sẽ trao đổi dữ liệu với nhau qua những câu truy vấn và câu phản hồi. Ứng với từng câu truy vấn, tác giả đề xuất sử dụng những các thuộc tính (tác giả gọi là model) ở hai mức độ là ứng với từng trường dữ liệu và ứng với cả câu truy vấn. Những thuộc tính này sẽ được cho điểm từ 0 đến 1 để phản ánh độ giống với profile đã biết trước đó của thuộc tính. Thực chất đây là giá trị xác suất phản ánh độ bình thường của thuộc tính. Giá trị p càng tiến về 0 có nghĩa là thuộc tính nói rằng giá trị quan sát được không giống với profile (báo hiệu nguy cơ có tấn công xảy ra). Ngược lại, nếu giá trị tiến về 1 thì thuộc tính đó nói rằng không có tấn công xảy ra với dữ liệu quan sát được. Ứng với từng câu truy vấn quan sát được thì nhóm tác giả đề xuất công thức tính điểm bất thường như sau:
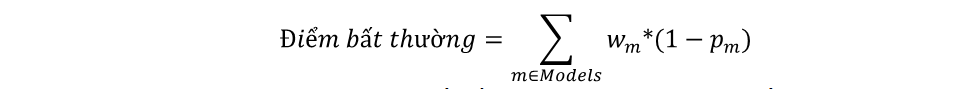
Bình luận: Khi thử nghiệm, chúng tôi thấy rằng công thức này chỉ chạy tốt trong trường hợp các câu truy vấn có ít thuộc tính. Khi câu truy vấn có nhiều thuộc tính điểm bất thường tổng của câu truy vấn có thể bị nhiễu. Để khắc phục trường hợp này, chúng tôi đề xuất sử dụng phương pháp máy học, cụ thể là cây quyết định để xác định tấn công. Phần kết quả chỉ ra rằng, cây quyết định là phù hợp trong trường hợp này.
Mô tả chi tiết các thuộc tính sử dụng
a. Chiều dài của trường dữ liệu
Các tác giả cho rằng chiều dài của trường dữ liệu gửi lên từ trình duyệt của người dùng hoặc là cố định (ví dụ như trong trường hợp của định danh của phiên làm việc - session identifier). Trong phần lớn các trường hợp độ biến thiên của chiều dài này là không cao. Tuy nhiên, trong trường hợp bị tấn công thì độ dài của trường dữ liệu rất có thể sẽ thay đổi. Ví dụ trong trường hợp của SQL injection, XSS. Do đó, tác giả đề xuất sử dụng sự thay đổi chiều dài nhằm nhận dạng tấn công từ người dùng.
Giai đoạn học: Cho tập chiều dài của các dữ liệu được nhập vào là l1, l2,…ln, Giá trị trung bình µ và phương sai α2 của tập dữ liệu.
Giai đoạn phát hiện tấn công: Cho trước µ và α2 là giá trị trung bình và phương sai của tập dữ liệu, các tác giả tìm cách tính xác suất P(l) để giá trị của tham số có độ dài là l có thể xảy ra. Điều đó được thực hiện dựa vào bất phương trình Chebyshev. Theo đó:
với ý nghĩa là cho bất kỳ phân phối xác suất có giá trị trung bình µ và phương sai α2 thì chọn trước một giá trị x (thuộc phân phối xác suất này) thì sự sai lệch của x so với trung bình µ lớn hơn một ngưỡng t bất kỳ bị chặn bởi 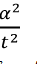
P(|x-µ|>|l-µ|): xác suất để biến ngẫu nhiên x, xa µ hơn l xa µ. Giá trị xác suất này càng nhỏ nghĩa là l càng khó xảy ra. Giá trị này càng lớn thì chứng tỏ l càng gần với giá trị trung bình có nghĩa là phần còn lại rất có khả năng xảy ra.
b. Phân bố thuộc tính ký tự
Theo quan sát thì phần lớn các trường có một số ký tự nhất định. Và phần lớn nhóm ký tự này chỉ bao gồm 1 phần nhỏ của 256 ký tự trong bảng ASCII. Do đó, việc xác định sự bình thường, bất thường của câu truy vấn dựa vào sự phân bố ký từ là có cơ sở. Theo tác giả, chúng ta khó có thể kỳ vọng là sự phân bố ký tự này của các lần xuất hiện của cùng một trường là giống nhau. Để làm cho độ đo có thể chấp nhận được sự sai lệch này, tác giả đề xuất sử dụng vector tần suất xuất hiện của ký tự sau khi được xấp xếp theo thứ tự giảm dần. Có nghĩa là sau khi thống kê sự xuất hiện của ký tự trong câu truy vấn, các giá trị tần suất sẽ được xấp xếp theo thứ tự giảm dần. Sự so sánh sẽ được thực hiện trên vector giá trị này. Theo các tác giả, trong hoàn cảnh bình thường, chúng ta kỳ vọng rằng các giá trị tần suất xuất hiện của ký tự giảm dần. Trong khi đó, trong trường hợp bị tấn công thì sẽ có hai trường hợp. Trường hợp một, giá trị tần suất giảm một cách đột ngột do sự có mặt của một số ký tự đặc biệt. Trường hợp thứ hai, các ký tự được tạo ngẫu nhiên nên sự phân bố này có khuynh hướng đồng đều. Tác giả gọi sự phân bố của các tần suất trong trường hợp không có tấn công là ICD. Giá trị tần số thông dụng thứ i được xác định bởi ICD(i).
Giai đoạn học: Trong giai đoạn này, thuật toán đề xuất xây dựng các ICD. Cho mỗi câu truy vấn, chúng ta tính lưu lại sự phân bố ký tự. Sau đó, ICD được tính như sau. Giá trị thứ i của ICD, ICD(i), được tính bằng giá trị trung bình của tất cả các phần tử i trong các phân bố ký tự đã được lưu trước đó. Dễ dàng suy ra rằng tổng của vector ICD bằng 1.
Phát hiện tấn công: Cho trước ICD, nhiệm vụ của chúng ta là làm sao xác định tham số tương ứng trong câu truy vấn có giá trị bình thường hay bất thường. Chúng ta thực hiện điều này bằng việc xác định xác suất để vector tần số là một mẩu được rút ra từ cùng một phân phối với ICD. Điều đó được thực hiện bằng một phép thử xác suất. Phục vụ cho mục đích này, các tác giả đề xuất sử dụng chi-squared test (goodness of fit). Tác giả đề xuất, ứng với các vector ICD, chúng ta gom chúng lại thành 6 nhóm khác nhau (gọi là bins).
Khi có câu truy vấn mới vào, chúng ta tính tần suất xuất hiện để xây dựng thành một vector 256 giá trị. Sau đó, vector này được chuyển thành vector có sáu giá trị dựa vào bảng trên. Sau đó, chúng ta thực hiện phép thử chi-squared nhằm xác định xem giá trị quan sát được có cùng phân phối với ICD. Để thực hiện điều đó, chúng ta tiến hành các bước sau:
1. Tính giá trị quan sát và giá trị kỳ vọng. Giá trị quan sát cho mỗi bin đã được tính ở trên
2. Tính
Bình luận: Theo quan sát của chúng tôi, hầu hết các trường dữ liệu đều có kích thước ngắn. Do đó, phân phối ký tự này hầu như không sử dụng được trong nhiều trường hợp.
c. Token Finder
Thuộc tính này nhằm đánh giá xem giá trị của một trường có nằm trong một tập hữu hạn hay không (ví dụ như các trường thể hiện giới tính, trình độ học vấn…). Trong trường hợp tấn công, giá trị của trường này khi đó sẽ khác hẳn và do đó bị phát hiện.
Giai đoạn học:
Nhóm tác giả cho rằng có thể phân biệt một trường có giá trị ngẫu nhiên hay thuộc một tập hữu hạn bằng cách đếm số giá trị khác nhau mà trường đó có thể mang. Nếu xuất phát từ tập cố định thì giá trị này sẽ bị giới hạn bởi một ngưỡng t nào đó. Ngược lại, nó sẽ không có chặn trên. Độ đo để xác định mức độ ngẫu nhiên của giá trị được định nghĩa là tỉ lệ giữa số giá trị khác nhau mà trường đó thể hiện trên tổng số lần mà chúng được quan sát. Nếu tỉ lệ này tăng thì có nghĩa là trường đó mang giá trị ngẫu nhiên. Ngược lại, giá trị của trường xuất phát từ một tập hữu hạn. Cụ thể hơn, định nghĩa hai hàm f và g cho trường dữ liệu a như sau:

Nếu giá trị P nhỏ hơn không, f và g không cùng xu hướng nên trường dữ liệu được cho là xuất phát từ một tập dữ liệu hữu hạn. Thật vậy, trong trường hợp này số lượng giá trị của f(x) tăng (tương ứng với số mẩu phân tích tăng) thì giá trị của g(x) lại giảm (tương ứng với số giá trị riêng biệt giảm). Ngược lại, trong trường hợp P lớn hơn không thì x được cho là ngẫu nhiên.
Trong trường hợp chúng ta nghĩ rằng đó là một tập giá trị nhất định chúng ta sẽ lưu tập giá trị quan sát được để sử dụng trong giai đoạn phát hiện tấn công.
Giai đoạn phát hiện tấn công: Trong trường hợp tập giá trị được xác định là hữu hạn và nếu như giá trị quan sát được không thuộc các giá trị mà chúng ta đã lưu trước đó thì kết quả trả về là 1. Trong các trường hợp còn lại, chúng ta trả về giá trị 0.
d. Có xuất hiện ký tự mới
Trong quá trình học chúng tôi sẽ lưu lại tập ký tự đã xuất hiện. Trong giai đoạn phát hiện tấn công, nếu xuất hiện một ký tự mới chúng tôi sẽ xem như một điểm nghi ngờ tấn công do đó xác suất bình thường sẽ giảm xuống.
e. Có sự xuất hiện của từ khóa
Chúng tôi đề xuất một tập các từ khóa hay được sử dụng khi tấn công web. Trong quá trình học, nếu không có sự xuất hiện của các ký tự này mà xuất hiện trong giai đoạn phát hiện tấn công thì cũng được xem là dấu hiệu của tấn công.
f. Sự vắng mặt của thuộc tính
Các tác giả quan sát rằng câu truy vấn lên máy chủ thông thường được thực hiện tự động. Thực tế, các câu truy vấn này là kết quả của quá trình xử lý của các chương trình client-sides, HTML, scripts và do đó, số lượng, thứ tự các trường thông thường là cố định. Do đó, dựa vào yếu tố này chúng ta có thể phát hiện một số loại tấn công.
Giai đoạn học: Ứng với mỗi câu truy vấn, chúng ta liệt kê các trường có trong câu truy vấn Sq={ai,…ak} trong giai đoạn học.
Giai đoạn phát hiện tấn công: Trong giai đoạn phát hiện tấn công nếu một trường không xuất hiện trong tập đã được quan sát trước đó thì chúng ta sẽ cảnh báo tấn công.
g. Trật tự của các thuộc tính
Mục đích là chúng ta sẽ xây dựng đồ thị biểu diễn thứ tự xuất hiện của câu truy vấn.
Giai đoạn học: Các tác giả xây dựng đồ thị có hướng biểu diễn thứ tự của các thuộc tính ở tất cả các câu truy vấn. Để làm được việc này, trong giai đoạn học, tập các trường sẽ được ghi nhận. Mỗi trường sẽ được biểu diễn bằng một đỉnh trên đồ thị có hướng G. Ứng với mỗi câu truy vấn nếu trường ai xuất hiện trước aj thì sẽ có một cạnh có hướng đi từ ai đến aj.
Giai đoạn phát hiện tấn công: Giai đoạn phát hiện tấn công thì khi nhận được một câu truy vấn với các trường dữ liệu là a1, a2, …, ai và một trật tự ràng buộc thứ tự O, tất cả các cặp (aj,ak) với j khác k và 1<=j và k<=i được kiểm tra với O để phát hiện bất thường. Một cặp được (aj, ak) được gọi là bất thường khi cặp (ak,aj) tồn tại trong O. Nếu có trường hợp bất thường xảy ra giá trị p là 0. Ngược lại, giá trị bất thường p là 1.
III. CÀI ĐẶT VÀ ĐÁNH GIÁ
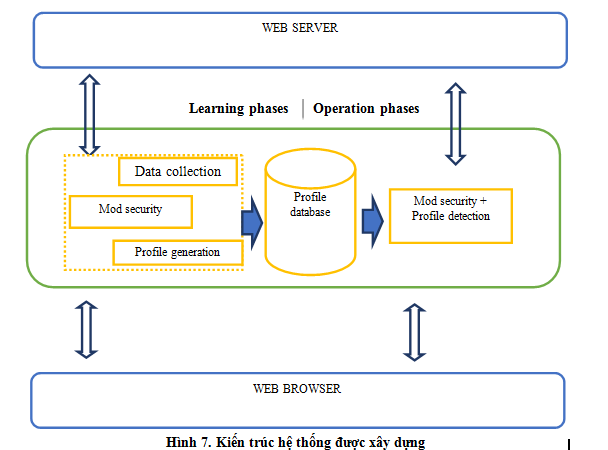
Kiến trúc tổng quan được trình bày như trong Hình 7. Trong đó, hệ thống hoạt động ở hai giai đoạn. Trong giai đoạn học, ModSecurity vẫn sử dụng bộ signature để phát hiện tấn công. Song song với đó, hệ thống tiến hành thu thập dữ liệu nhằm xây dựng profile. Ở cuối giai đoạn học, hệ thống áp dụng các kỹ thuật trình bày ở phần II để xây dựng Profile. Ở giai đoạn vận hành, chương trình được cài đặt chạy song song bộ luật chuẩn của ModSecurity và sử dụng profile.
Dataset
Chúng tôi sử dụng tập dữ liệu CSIC 2010 (http://www.isi.csic.es/dataset/) chuyên để thử nghiệm các giải pháp tường lửa ứng dụng web được đề xuất bởi Viện An toàn Thông tin thuộc Hội đồng Nghiên cứu Quốc gia Tây Ban Nha. Trong tập dữ liệu này có tổng cộng 36.000 câu truy vấn an toàn và 25.000 câu truy vấn có tấn công. Tập dữ liệu chứa hầu hết các loại tấn công phổ biến của ứng dụng web.
Kết quả đạt được
Chúng tôi sử dụng weka khi sử dụng thuật toán cây quyết định J48 trên tập dữ liệu CSIC 2010 và kết quả thu được như Hình 8:
Hình 8. Kết quả đạt được
IV. KẾT LUẬN
Để phát triển tường lửa ứng dụng web có khả năng tự học và phát sinh ra các luật, nhóm nghiên cứu đánh giá bằng thực nghiệm và kết luận ModSecurity là tường lửa thích hợp nhất để phát triển thêm các tính năng. Thật vậy, ModSecurity có tính chính xác cao hơn các tường lửa mã nguồn mở khác trong thực nghiệm và hỗ trợ reverse proxy. Trên cơ sở lựa chọn này, chúng tôi trình bày cơ chế hoạt động của ModSecurity và cơ chế để can thiệp vào luồng dữ liệu trong trường hợp có sử dụng mã hóa (HTTPS) và không mã hóa (HTTP). Chúng tôi cũng trình bày mô hình phát hiện tấn công dựa vào profile mà chúng tôi sử dụng trong việc phát hiện tấn công (mô hình này được kế thừa, cải tiến từ [24]). Kế đến, chúng tôi đã cài đặt và thử nghiệm hệ thống với các loại tấn công web phổ biến. Kết quả cho thấy hệ thống có thể phân biệt các tấn công dựa vào profile đối với tập dữ liệu CSIC 2010. Kết quả thử nghiệm cho thấy kết quả phát hiện tấn công khá cao (96%). Nhóm nghiên cứu cũng tiến hành đánh giá 5 website ở Bình Dương. Trong đó, chúng tôi đã triển khai thực tế giải pháp để bảo vệ website Bàu Bàng. Qua đánh giá, sau khi tinh chỉnh các luật thì hệ thống đã ngăn chặn được các tấn công khai thác lỗ hổng của website này.
e. Thời gian nghiên cứu: 18 tháng
- Thời gian bắt đầu: 03/2015
- Thời gian kết thúc: 03/2016
f. Kinh phí thực hiện: 519.200.000 đồng (Kinh phí được cấp: 445.000.000 đồng)
(Có thể tìm đọc toàn văn Báo cáo kết quả nghiên cứu của dự án tại Trung tâm Thông tin và Thống kê khoa học và công nghệ).